Scheduling In Go : Part II – Go Scheduler
介绍
在本调度系列的第一部分中,我解释了操作系统调度程序的各个方面,我认为这些方面对于理解和欣赏 Go 调度程序的语义很重要。在这篇文章中,我将从语义层面解释 Go 调度程序的工作原理,并关注高级行为。 Go 调度器是一个复杂的系统,小的机械细节并不重要。重要的是有一个好的模型来了解事物的工作方式和行为方式。这将使您能够做出更好的工程决策。
Your Program Starts
当你的 Go 程序启动时,它会为主机上识别的每个虚拟内核分配一个逻辑处理器 (P)。如果你有一个处理器,每个物理核心有多个硬件线程(超线程),每个硬件线程都将作为一个虚拟核心呈现给你的 Go 程序。为了更好地理解这一点,请查看我的 MacBook Pro 的系统报告。
Figure 1

你可以看到我有一个带有 4 个物理内核的处理器。该报告没有公开的是我每个物理内核拥有的硬件线程数。 Intel Core i7 处理器具有超线程,这意味着每个物理内核有 2 个硬件线程。这将向 Go 程序报告 8 个虚拟内核可用于并行执行 OS 线程。
要对此进行测试,请考虑以下程序:
Listing 1
package main
import (
"fmt"
"runtime"
)
func main() {
// NumCPU returns the number of logical
// CPUs usable by the current process.
fmt.Println(runtime.NumCPU())
}
当我在本地机器上运行这个程序时,NumCPU()函数调用的结果将是值8。 我在机器上运行的任何围棋程序都会得到8个P。
每个P被分配一个OS线程(“M”)。 “M”代表机器。 这个线程仍然是由操作系统管理的,并且操作系统仍然负责把线程放在内核上执行,就像在上一篇文章中解释的那样。 这意味着当我在我的机器上运行Go程序时,我有8个线程可以执行我的工作,每个线程单独连接到P。
每个 Go 程序都有一个初始的Goroutine(“G”),这是 Go 程序的执行路径。 Coroutine,但这是Go,所以我们把字母“C”换成“G”,就得到了“Goroutine”这个词。 您可以将Goroutines视为应用程序级别的线程,它们在许多方面与OS线程类似。 就像OS线程可以在上下文中打开和关闭一个核心一样,Goroutines也可以在上下文中打开和关闭一个M。
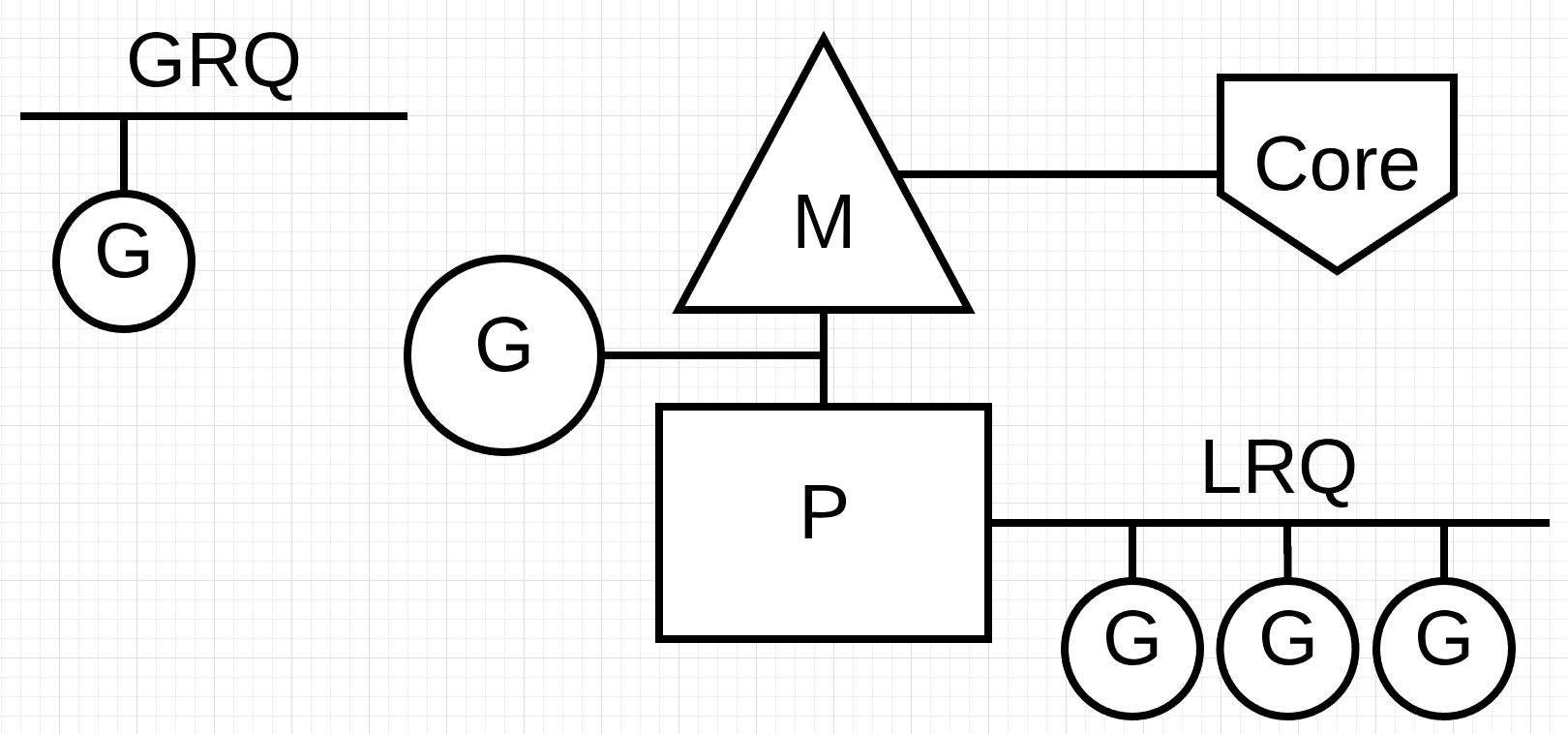
最后一块难题是运行队列。 Go调度器中有两个不同的运行队列:全局运行队列(GRQ)和本地运行队列(LRQ)。 每个P都有一个LRQ,用于管理分配给P的上下文中执行的Goroutines。这些Goroutines轮流在上下文中打开和关闭分配给P的M。GRQ用于还没有分配给P的Goroutines。 有一个将Goroutines从GRQ移到LRQ的过程,我们将在后面讨论这个过程。
图2展示了所有这些组件。
Figure 2
协作调度
正如我们在第一篇文章中所讨论的,OS调度器是一种抢占式调度器。本质上,这意味着您无法预测调度程序在任何给定时间会做什么。内核在做决定,一切都是不确定的。运行在操作系统之上的应用程序无法通过调度控制内核内部发生的事情,除非它们利用了atomic指令和mutex调用等同步原语。
Go调度程序是Go运行时的一部分,并且Go运行时内置在应用程序中。 这意味着Go调度器运行在内核之上的user space中。 目前的Go调度器的实现不是抢占式调度器,而是协作式调度器。 作为一个协作(cooperating)调度器意味着调度器需要定义良好的用户空间事件,这些事件发生在代码中的安全点,以做出调度决策。
Go 协作调度程序的出色之处在于它看起来和感觉都是抢先的。你无法预测 Go 调度器会做什么。这是因为这个协作调度器的决策不在开发人员手中,而是在 Go 运行时。将 Go 调度器视为抢占式调度器很重要,并且由于调度器是非确定性的,因此这并没有太大的延伸。
协程状态 (Goroutine States)
就像线程一样,Goroutines也有相同的三种高级状态。 它们决定了Go调度器在任何给定的Goroutine中所扮演的角色。 一个Goroutine可以处于三种状态之一:Waiting, Runnable or Executing.
Waiting: 这意味着 Goroutine 被停止并等待某些东西才能继续。这可能是由于等待操作系统(系统调用)或同步调用(原子和互斥操作)等原因。这些类型的延迟(latencies)是性能不佳的根本原因。
Runnable: 这意味着Goroutine需要在M上花费时间,这样它才能执行分配给它的指令。 如果有很多需要时间的Goroutines,那么Goroutines必须等待更长的时间来获得时间。 此外,任何给定的Goroutine获得的单个时间量也会因为更多的Goroutine争夺时间而缩短。 这种类型的调度延迟也可能导致性能较差。
Executing: 这意味着Goroutine被放置在M上,并正在执行它的指令。 与应用程序相关的工作已经完成。 这是每个协程都想要的。
上下文切换 (Context Switching)
Go 调度程序需要定义良好的用户空间事件,这些事件发生在代码中的安全点以进行上下文切换。这些事件和安全点在函数调用中表现出来。函数调用对 Go 调度程序的健康至关重要。今天(使用 Go 1.11 或更低版本),如果您运行任何不进行函数调用的紧密循环,您将在调度程序和垃圾收集中造成延迟。函数调用在合理的时间范围内发生是至关重要的。
_Note: 有一个 1.12 的提议被接受,在 Go 调度程序中应用非合作抢占技术以允许抢占紧密循环。
Go 程序中发生的四类事件允许调度程序做出调度决定。这并不意味着它总是会发生在这些事件之一上。这意味着调度程序获得了机会。
go关键字的使用- 垃圾回收
- 系统调用
- 同步和编排
go 关键字的使用
关键字 go 是你创建 Goroutines 的方式。一旦创建了一个新的 Goroutine,它就会给调度器一个机会来做出调度决定。
垃圾回收
同步和编排由于GC使用自己的一组Goroutines运行,所以这些Goroutines需要在M上运行。这会导致GC产生大量调度混乱。然而,调度程序对于Goroutine正在做的事情是非常聪明的,它将利用这种智能来做出明智的决定。一个明智的决定是在GC期间将希望接触堆的Goroutine与那些不接触堆的Goroutine进行上下文切换。当GC运行时,会做出许多调度决策。
系统调用
如果 Goroutine 进行系统调用会导致 Goroutine 阻塞 M,有时调度程序能够将 Goroutine 从 M 上进行上下文切换,并将新的 Goroutine 上下文切换到同一个 M 上。但是,有时新的 M 是需要继续执行在 P 中排队的 Goroutines。下一节将更详细地解释这是如何工作的。
同步和编排
如果原子、互斥或通道操作调用将导致 Goroutine 阻塞,调度程序可以上下文切换一个新的 Goroutine 来运行。一旦 Goroutine 可以再次运行,它就可以重新排队并最终在 M 上切换回上下文。
异步系统调用 (Asynchronous System Calls)
当您运行的操作系统能够异步处理系统调用时,可以使用称为 network poller的东西更有效地处理系统调用。这是通过在这些各自的操作系统中使用 kqueue (MacOS)、epoll (Linux) 或 iocp (Windows) 来完成的。
我们现在使用的许多操作系统都可以异步处理基于网络的系统调用。 这就是网络轮询器得名的原因,因为它的主要用途是处理网络操作。 通过将网络轮询器用于网络系统调用,调度器可以在进行系统调用时防止Goroutines阻塞M。 这有助于保持M可用来执行P的LRQ中的其他Goroutines,而不需要创建新的Ms.这有助于减少操作系统上的调度负载。
了解其工作原理的最佳方法是运行一个示例。
Figure 3
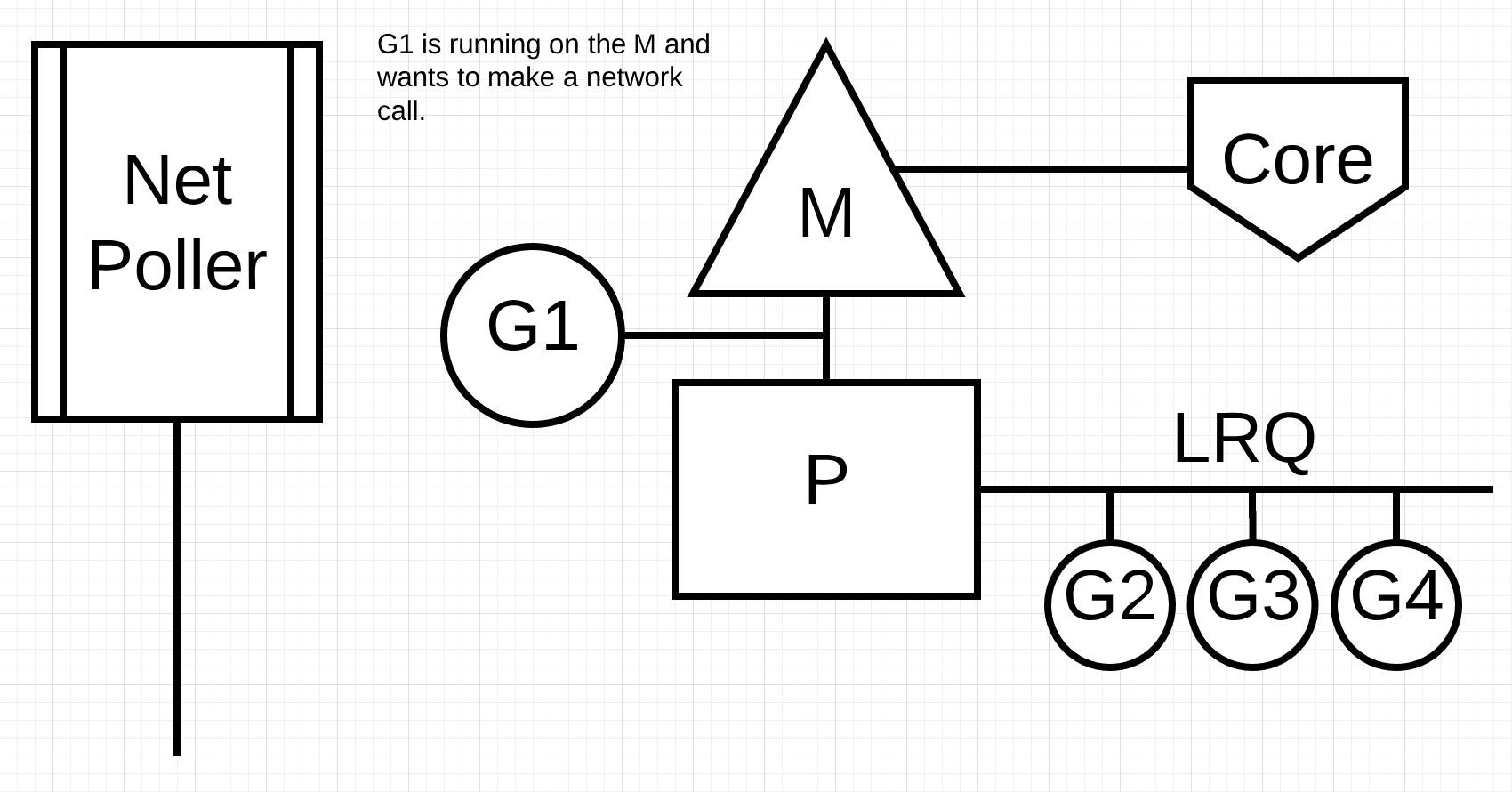
Figure 3 显示了我们的基本调度图。 Goroutine-1 正在 M 上执行,还有 3 个 Goroutine 在 LRQ 中等待以获取 M 上的时间。网络轮询器处于空闲状态,无事可做。
Figure 4
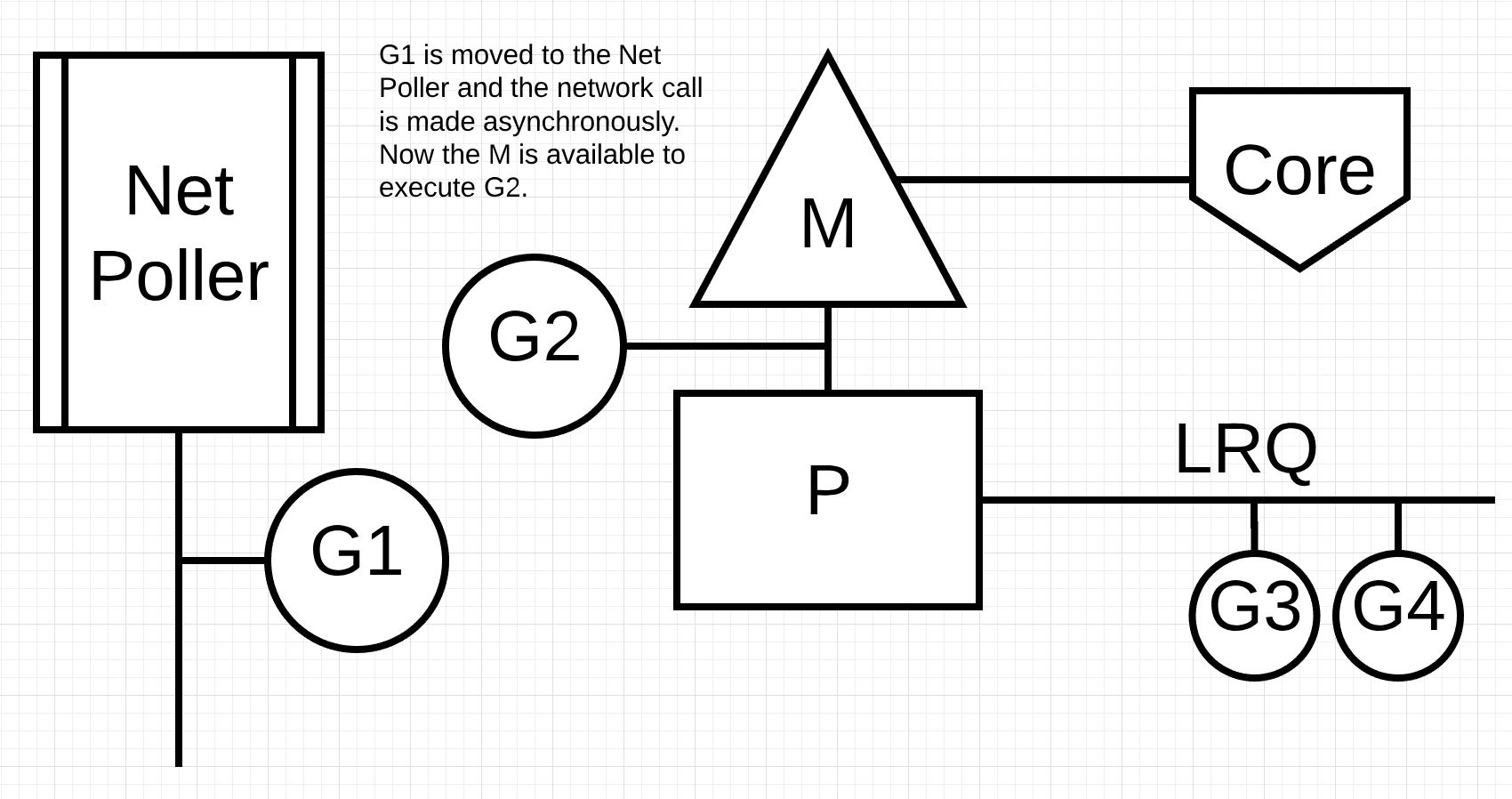
在 figure 4 中,Goroutine-1 想要进行网络系统调用,因此将 Goroutine-1 移至网络轮询器并处理异步网络系统调用。一旦 Goroutine-1 被移动到网络轮询器,M 现在可以用来执行 LRQ 中第一个 Goroutine。在上图中,Goroutine-2 在 M 上进行了上下文切换。
Figure 5
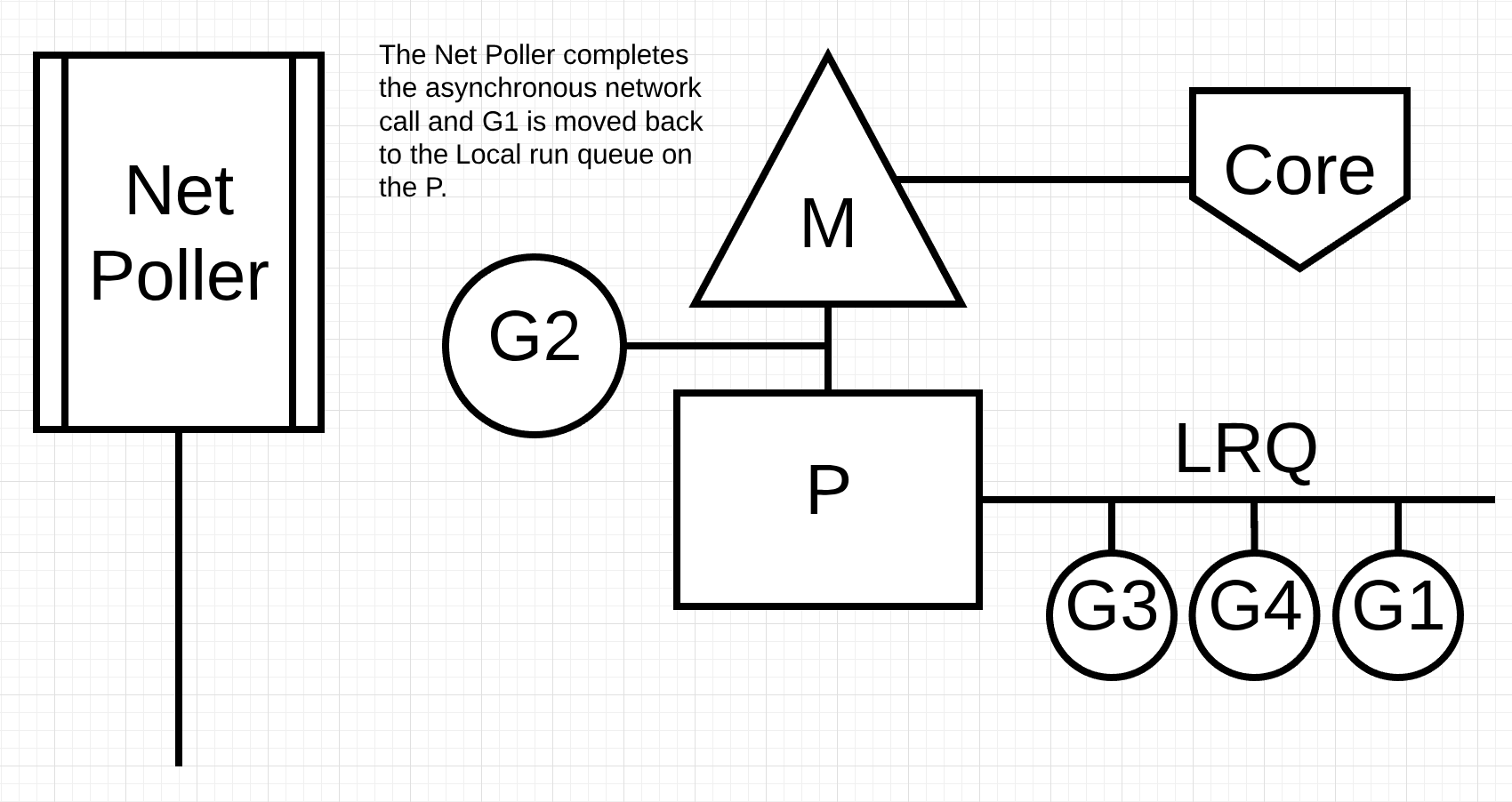
在 figure 5 中,Goroutine-1的异步网络系统调用由网络轮询器完成,并将 Goroutine-1 push到 P 的 LRQ。一旦 Goroutine-1 可以在 M 上进行上下文切换,它负责的 Go 相关代码可以再次执行。这里最大的好处是,要执行网络系统调用,不需要额外的 Ms。网络轮询器有一个操作系统线程,它一直在运行一个有效的事件循环。
同步系统调用 (Synchronous System Calls)
当Goroutine想要执行一个不能异步执行的系统调用时,会发生什么? 在这种情况下,不能使用网络轮询器,而进行系统调用的Goroutine将阻止m。这很不幸,但没有办法防止这种情况发生。 不能异步进行的系统调用的一个例子是基于文件的系统调用。 如果你正在使用CGO,在其他情况下调用C函数也会阻塞M。
Note: Windows操作系统确实能够异步地进行基于文件的系统调用。 从技术上讲,在Windows上运行时,可以使用网络轮询器。
让我们来看看会导致 M 阻塞的同步系统调用(如文件 I/O)会发生什么。
Figure 6
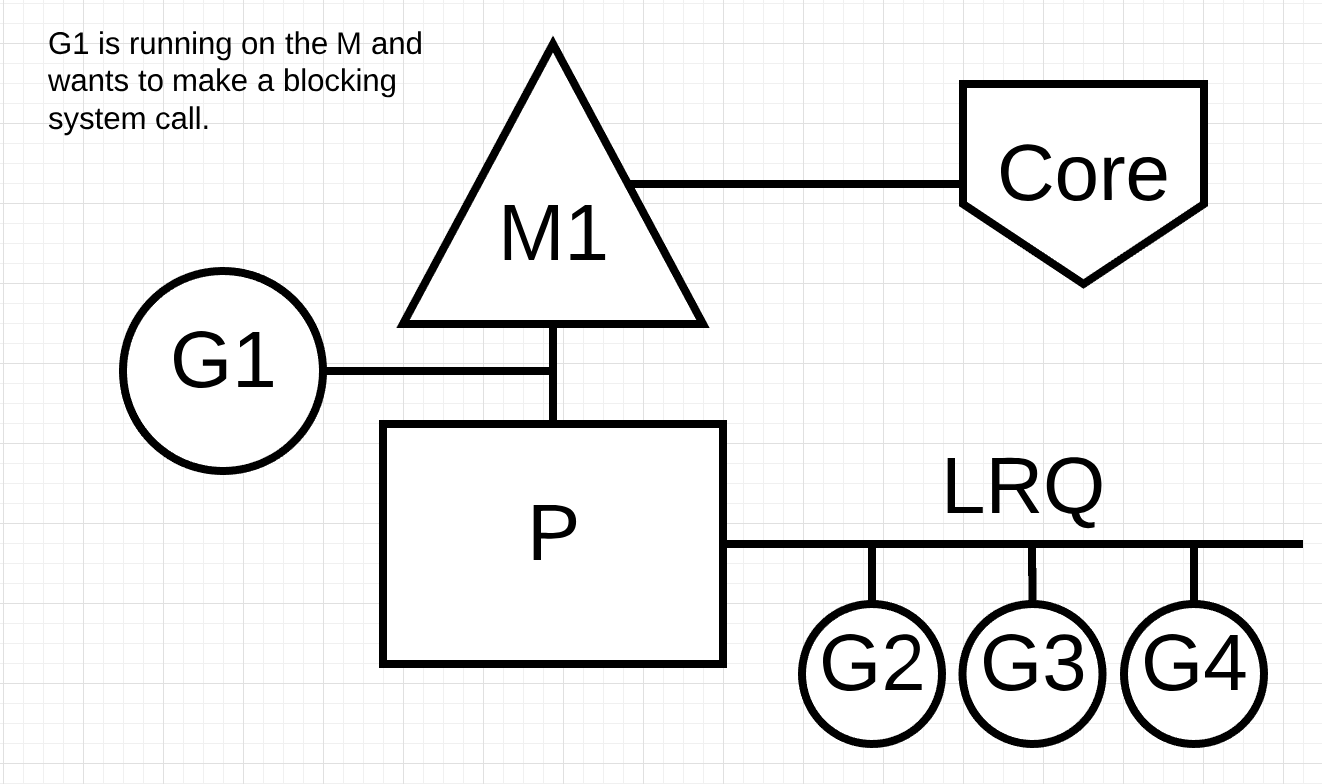
Figure 6 再次显示了我们的基本调度图,但这次 Goroutine-1 将进行同步系统调用,这将阻塞 M1。
Figure 7 M从P上移开,而阻塞G仍在。一个新的M被引入,现在G2被上下文切换
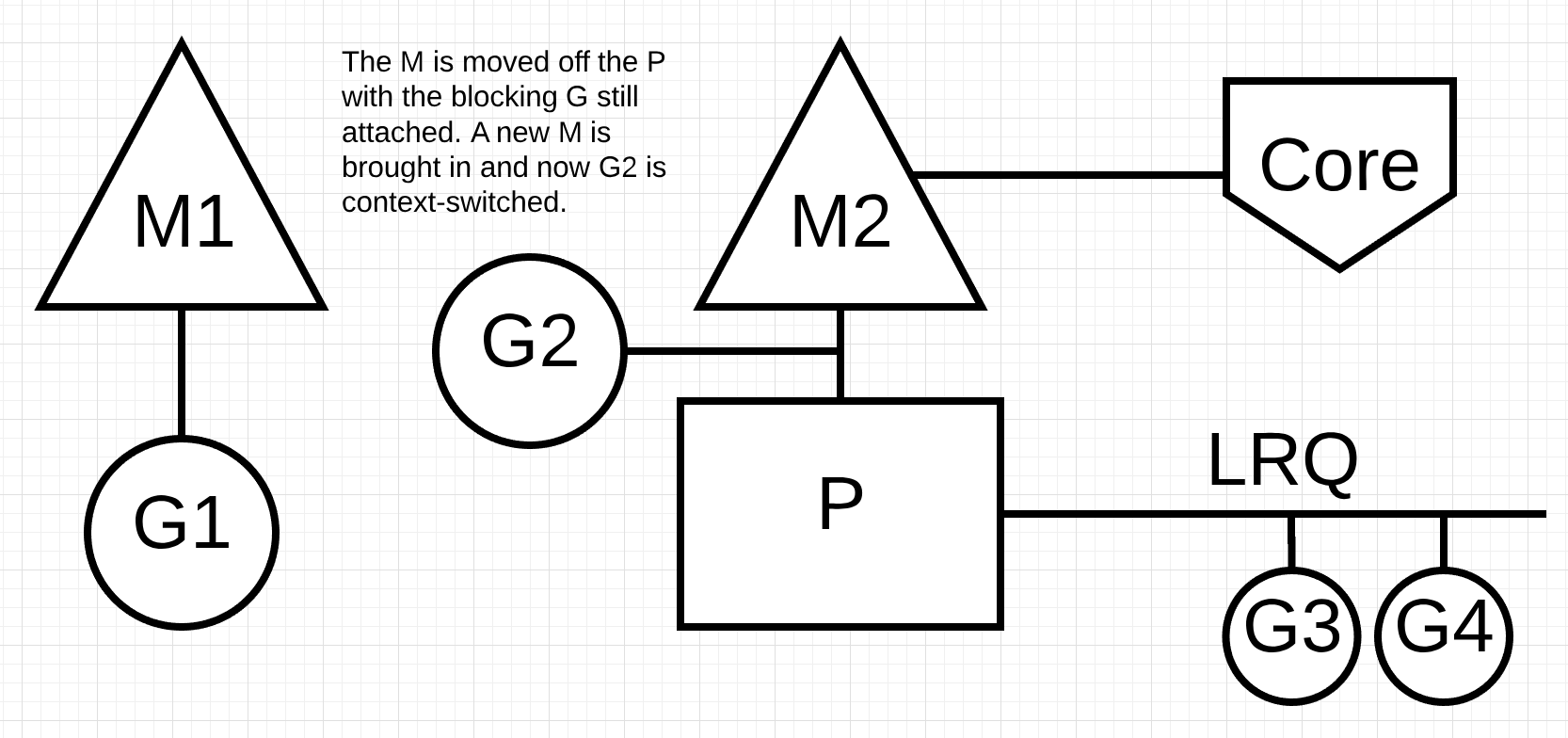
Figure 7 中,调度程序能够识别出 Goroutine-1 导致 M 阻塞。此时,调度程序将 M1 从 P 中分离出来,而阻塞的 Goroutine-1 仍然连接。然后调度器引入一个新的 M2 来为 P 服务。此时,可以从 LRQ 中选择 Goroutine-2 并在 M2 上进行上下文切换。如果由于先前的交换而已经存在 M,则此转换比必须创建新 M 更快。
Figure 8 一旦阻塞系统调用完成,G1被移回LRQ,然后m1被保存以备将来使用。
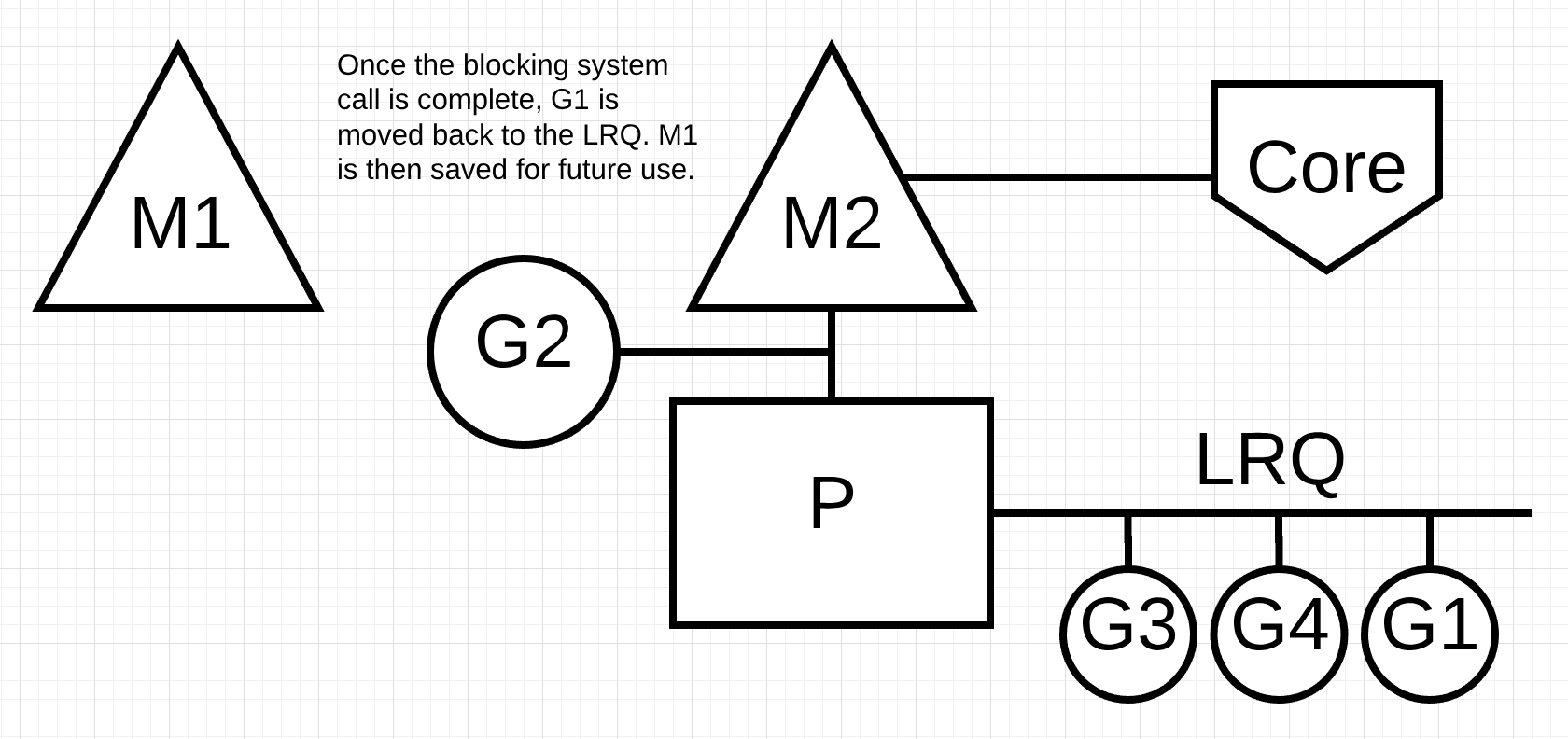
figure 8, Goroutine-1发出的阻塞系统调用结束。此时,Goroutine-1可以回到LRQ中,并再次由P提供服务。如果这种情况需要再次发生,M1将被放在一边以备将来使用。
工作窃取 (Work Stealing)
调度器的另一个方面是它是一个窃取工作的调度器。这在一些方面有助于保持计划的有效性。首先,你最不希望的事情是M进入等待状态,因为一旦这种情况发生,操作系统将上下文切换M离开核心。这意味着P无法完成任何工作,即使有一个处于可运行状态的Goroutine,直到M被上下文切换回Core上。“work stealing”还有助于在所有P中平衡Goroutines,从而更好地分配工作,更有效地完成工作。
让我们来看一个例子。
Figure 9 我们有两个P为四个G服务, GRQ中有一个G.
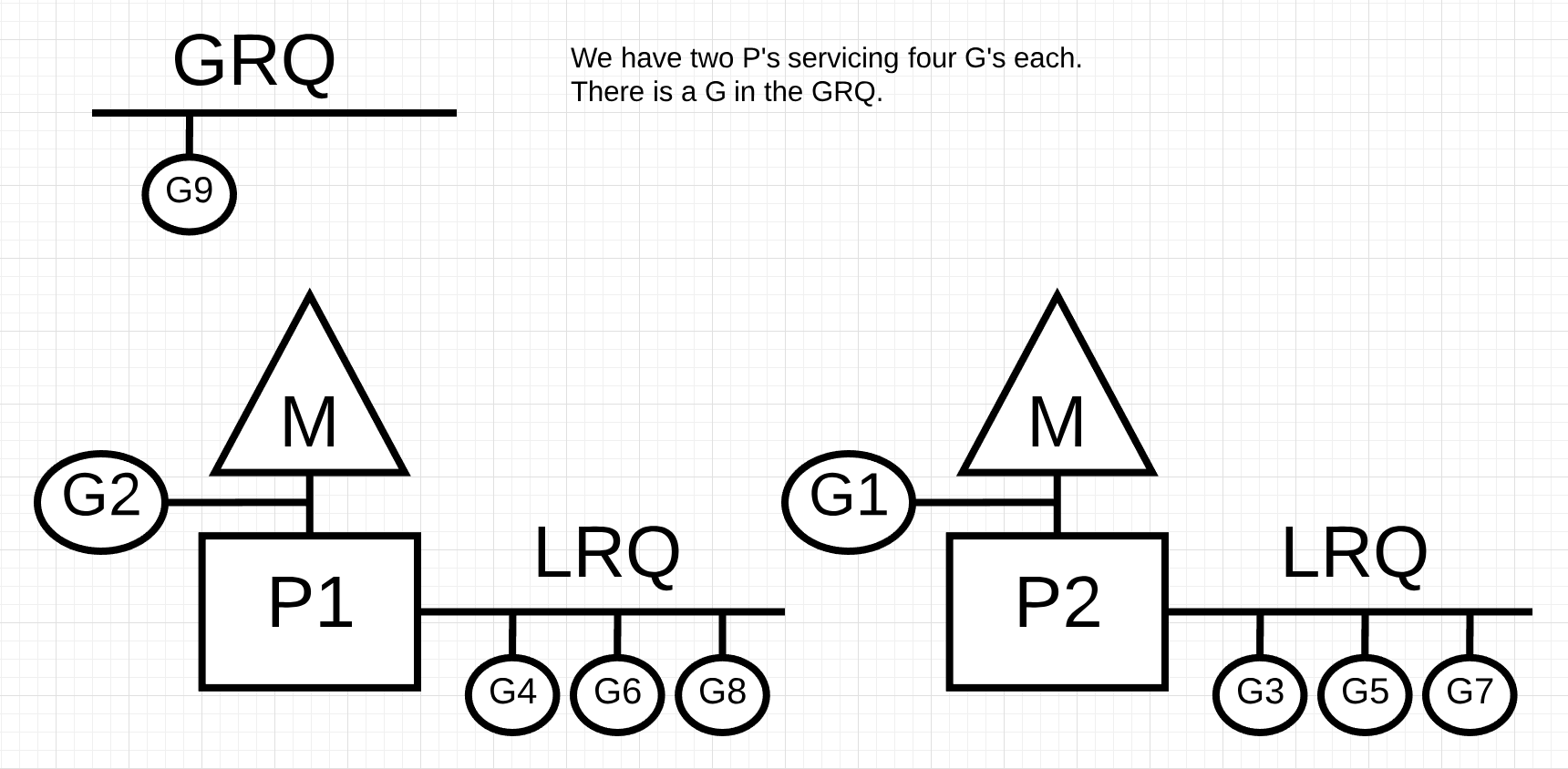
In figure 9, 我们有一个多线程的Go程序,两个P分别为四个Goroutine服务,GRQ中只有一个Goroutine。如果P的一个服务快速完成所有Goroutines,会发生什么?
Figure 10 P1服务完了它所有的G,现在它没有工作任务
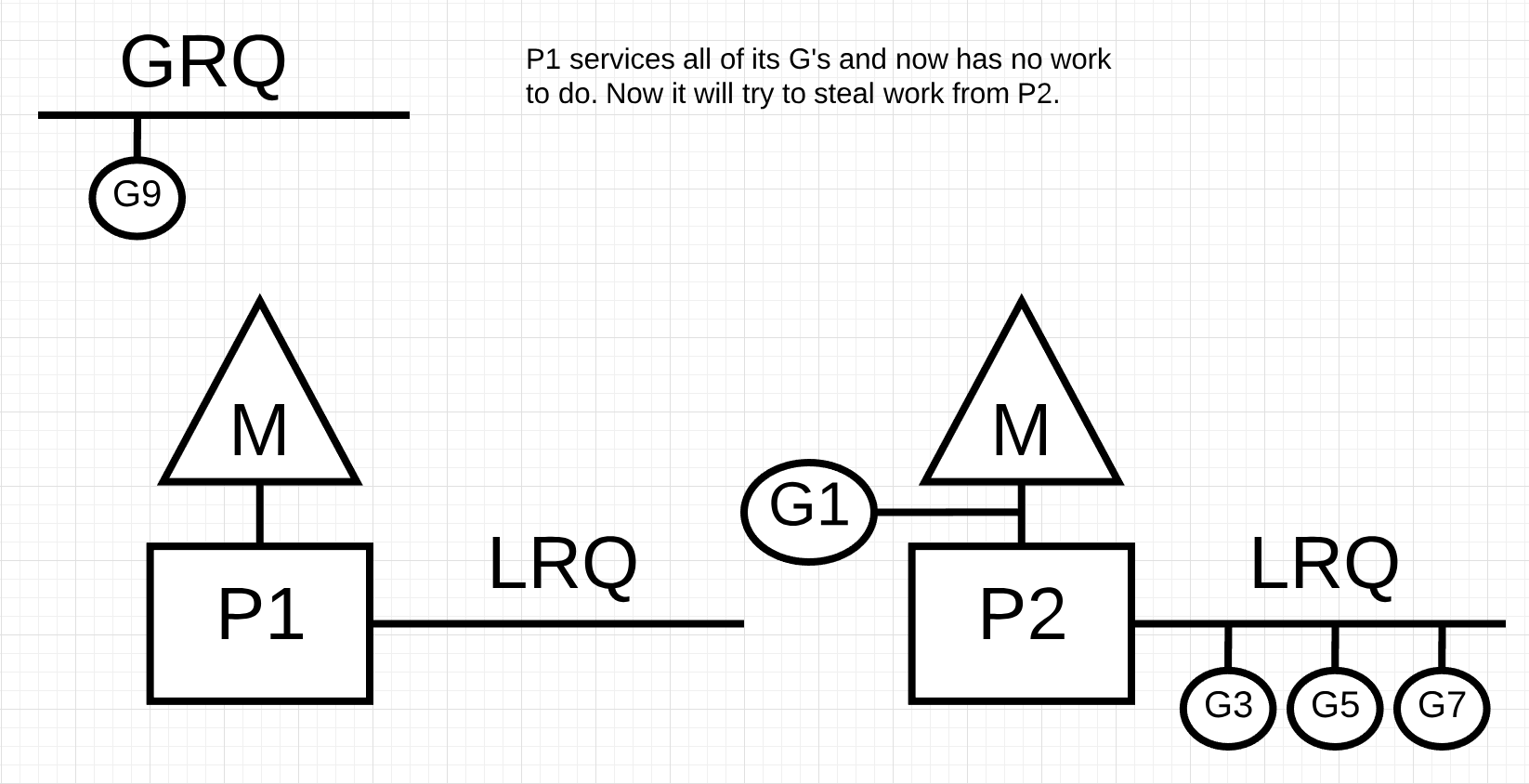
In figure 10, P1 没有更多的 Goroutines 可以执行。但是在 P2 的 LRQ 和 GRQ 中都有处于可运行状态的 Goroutine。这是 P1 需要窃取工作的时刻。窃取工作的规则如下。
Listing 2
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}
因此,根据Listing 2 中的这些规则,P1 需要检查 P2 的 LRQ 中的 Goroutines 并取其找到的一半。
Figure 11
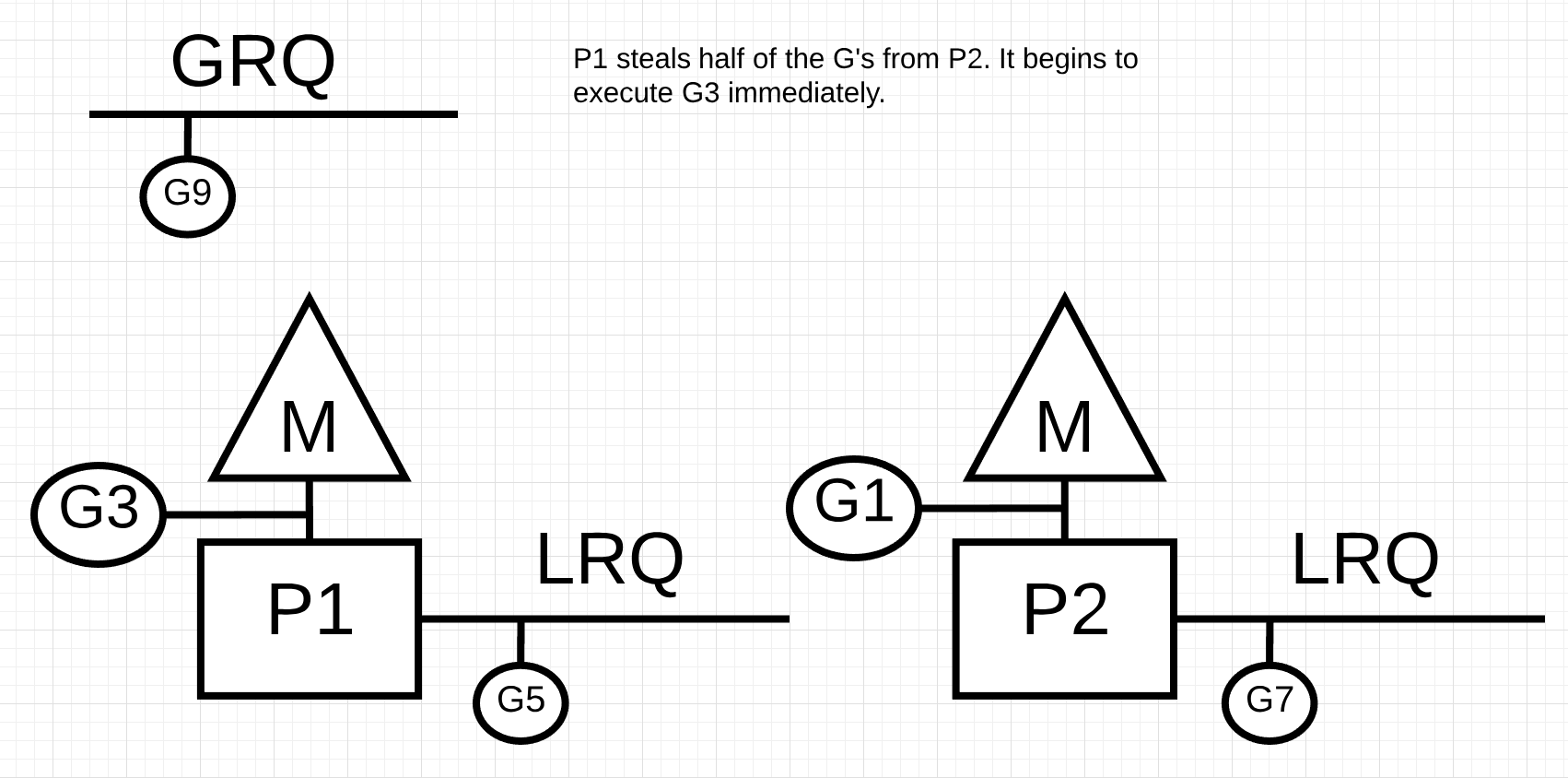
在figure 11中一半的 Goroutines 取自 P2,现在 P1 可以执行这些 Goroutines。
如果 P2 完成了所有 Goroutines 的服务并且 P1 的 LRQ 中没有任何东西会发生什么?
Figure 12
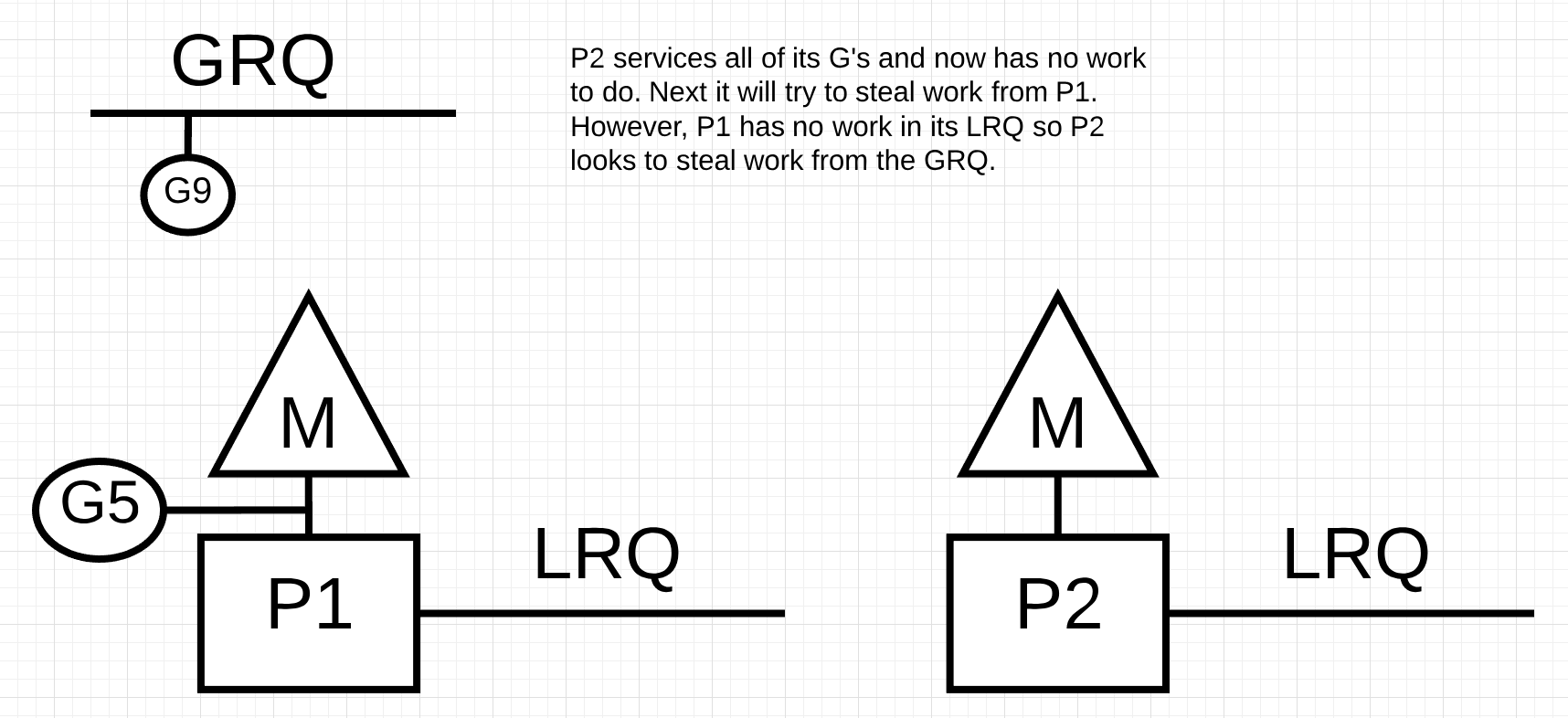
在figure 12中, P2完成了它所有的G的工作, 现在它需要去窃取一些G, 首先, 它会先去寻找P1的LRQ, 但是找不到任何G. 接下来它回去GRQ寻找G, 在这里它找到了 Goroutine-9.
Figure 13
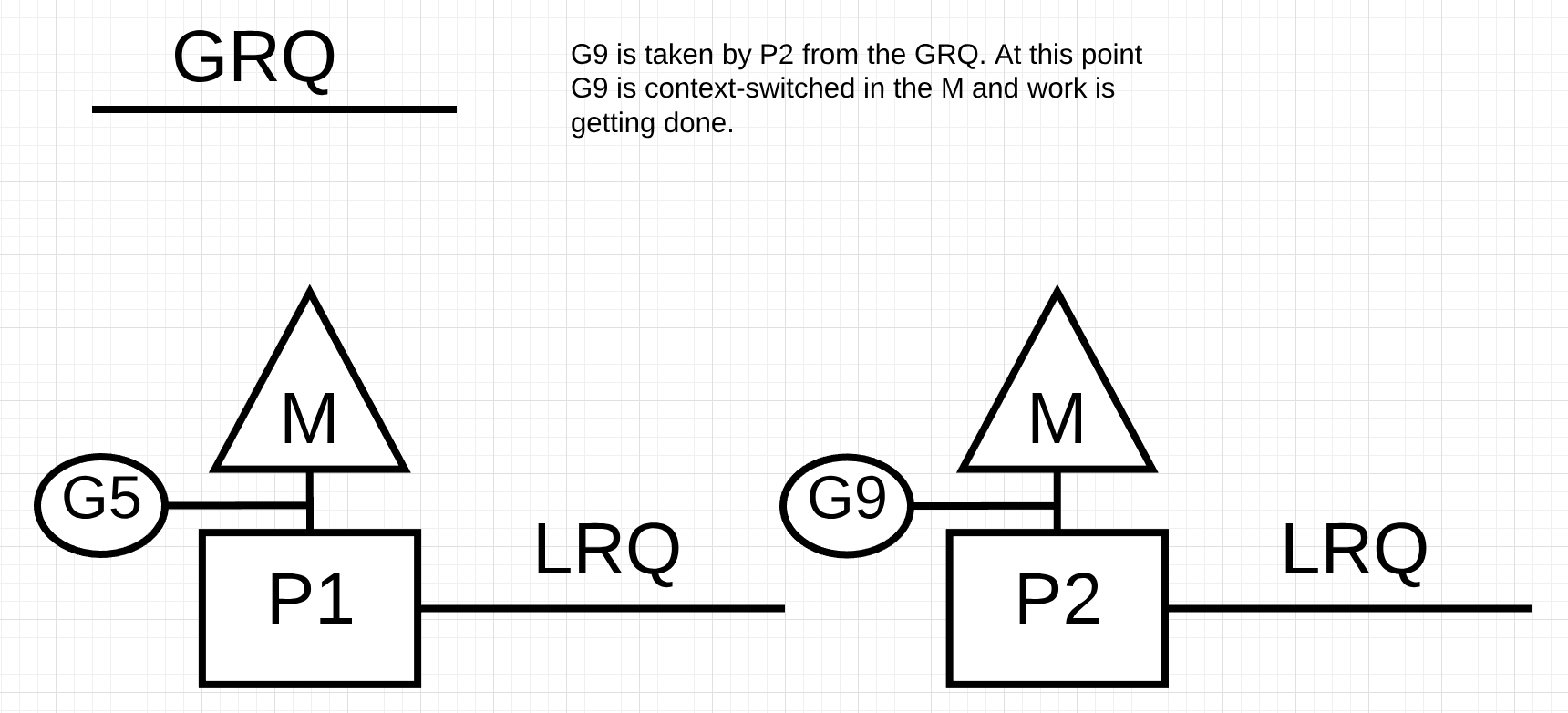
In figure 13, P2从GRQ中窃取了Goroutine-9并开始执行工作。这种“偷功”的好处在于,它让Ms们保持忙碌,而不是闲着。这种窃取工作在内部被认为是旋转m。这种旋转还有其他好处,JBD在她的“work-stealing ”博客文章中解释得很好。
实际的例子 (Practical Example)
有了机制和语义,我想向您展示所有这些如何结合在一起,以允许 Go 调度程序随着时间的推移执行更多工作。想象一个用 C 语言编写的多线程应用程序,其中程序正在管理两个操作系统线程,这些线程彼此来回传递消息。
Figure 14
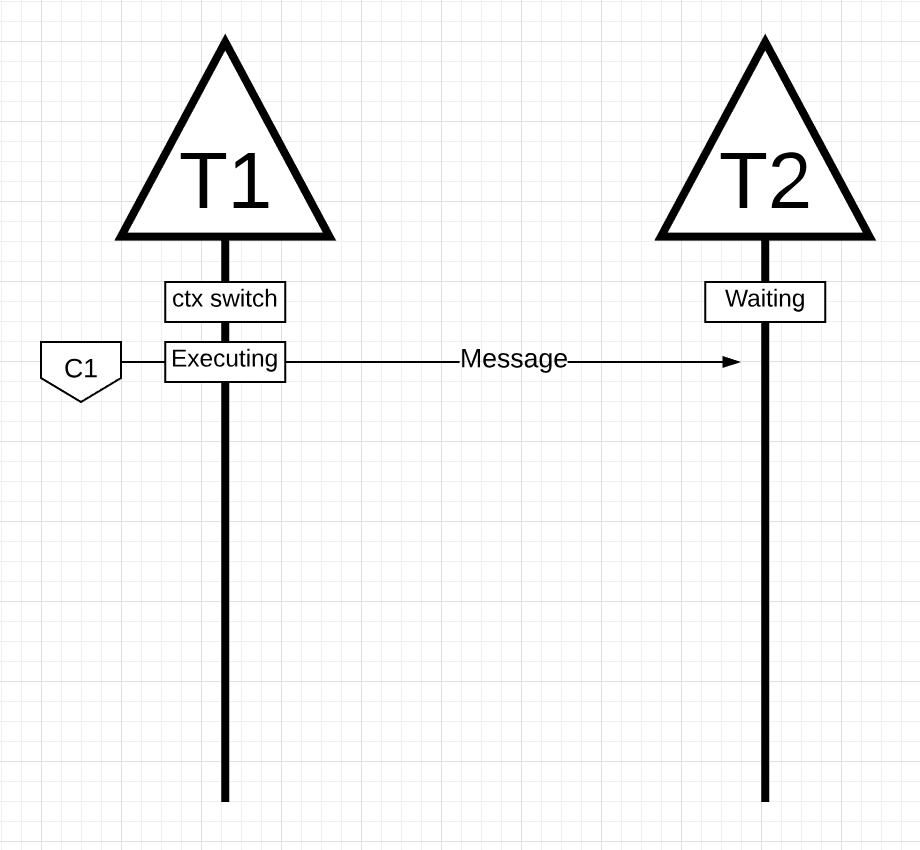
In figure 14, 有两个线程来回传递消息。线程1在核心1上进行了上下文切换,现在正在执行,这允许线程1向线程2发送消息。
Note: 这消息是如何传递的并不重要。重要的是在这个业务流程进行时线程的状态
Figure 15
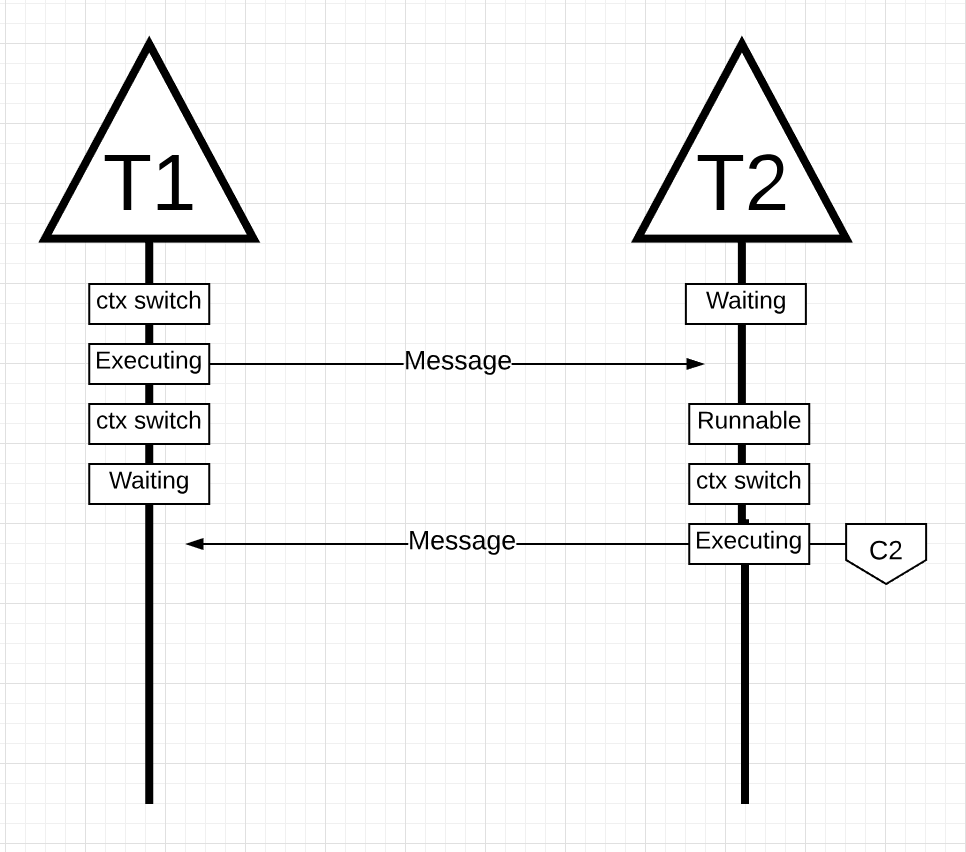
In figure 15, 一旦线程 1 完成发送消息,它现在需要等待响应。这将导致线程 1 被上下文关闭核心 1 并进入等待状态。一旦线程 2 收到有关消息的通知,它就会进入可运行状态。现在操作系统可以执行上下文切换并让线程 2 在核心上执行,它恰好是核心 2。接下来,线程 2 处理消息并将新消息发送回线程 1。
Figure 16
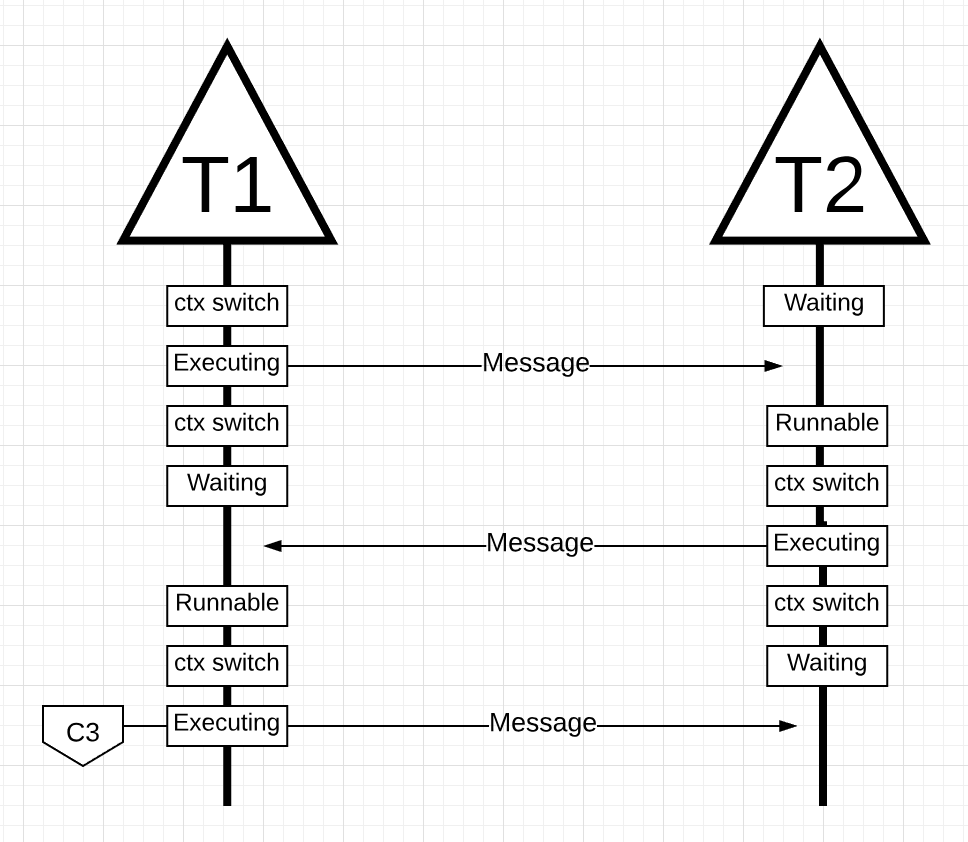
In figure 16, 当线程 2 的消息被线程 1 接收时,线程再次进行上下文切换。现在,线程 2 从执行状态切换到等待状态,线程 1 从等待状态切换到可运行状态,最后返回到一个执行状态,它允许它处理和发回一条新消息。
所有这些上下文切换和状态更改都需要时间来执行,这限制了完成工作的速度。由于每个上下文切换可能会导致约 1000 纳秒的延迟,并且希望硬件每纳秒执行 12 条指令,您正在查看或多或少的 12k 条指令,这些指令在这些上下文切换期间未执行。由于这些线程也在不同的核心之间弹跳,因此由于缓存线未命中而导致额外延迟的可能性也很高。
让我们以同样的例子为例,但使用Goroutines和Go调度器。
Figure 17
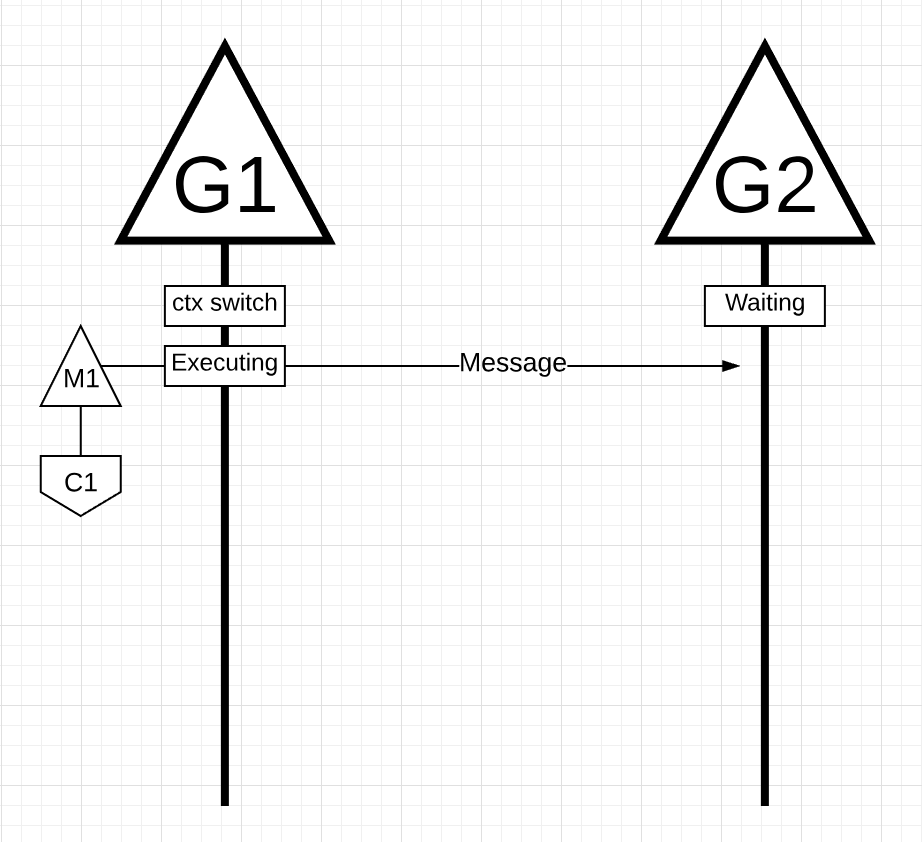
In figure 17, 有两个相互编排的goroutine来回传递消息。G1在M1上进行上下文切换,而M1恰好运行在Core 1上,这允许G1执行它的工作。G1的工作是将其消息发送给G2。
Figure 18
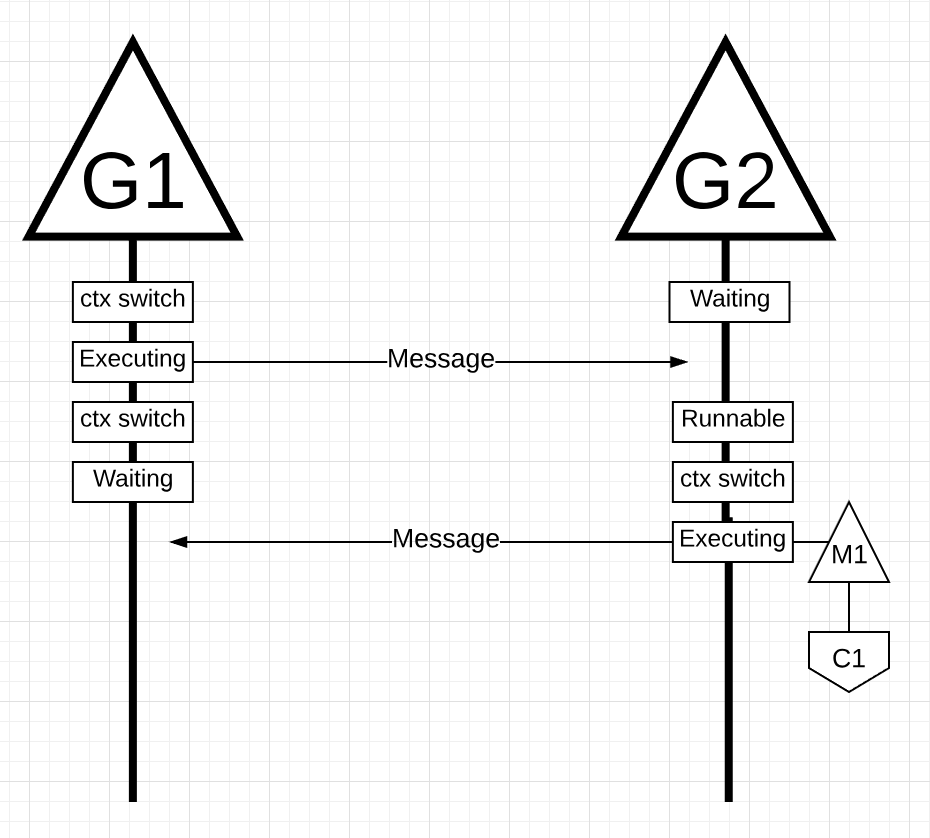
In figure 18, 一旦G1完成发送消息,它现在需要等待响应。这将导致G1被上下文切换到M1,并进入等待状态。一旦G2收到关于该消息的通知,它就进入可运行状态。现在Go调度器可以执行一个上下文切换,并让G2在M1上执行,M1仍然在Core 1上运行。接下来,G2处理该消息并将一条新消息发送回G1。
Figure 19
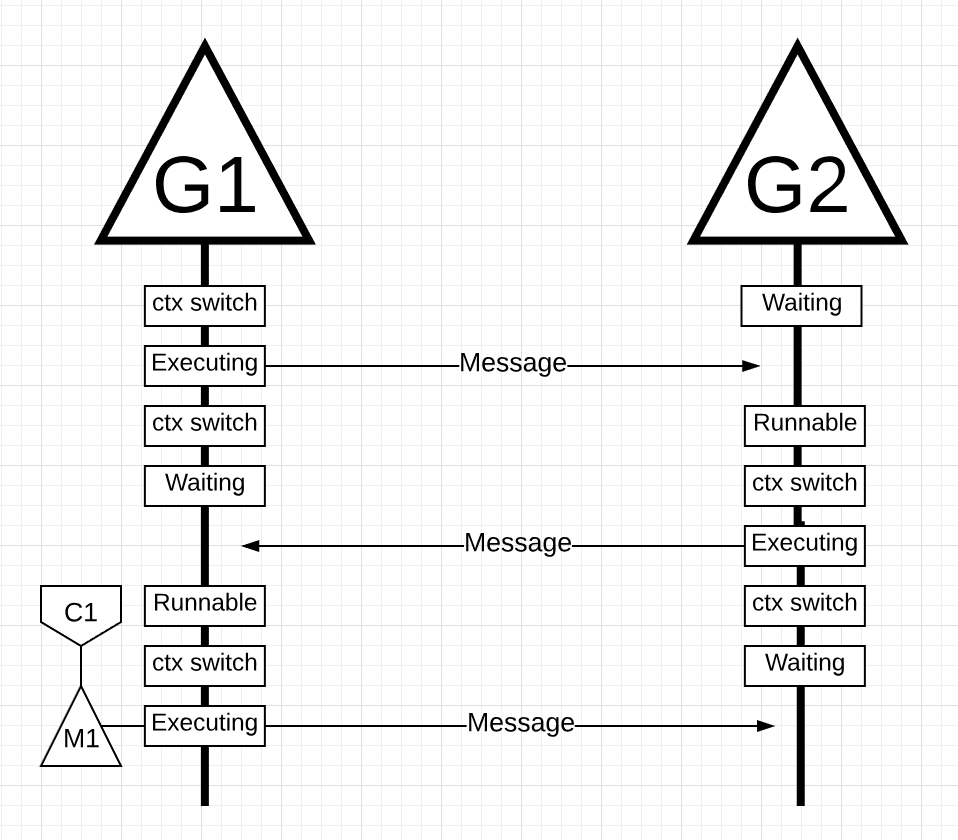
In figure 19, 当G2发送的消息被G1接收时,事情再次进行上下文切换。现在,G2上下文—从执行状态切换到等待状态,G1上下文—从等待状态切换到可运行状态,并最终返回到执行状态,这允许它处理并发回一个新消息。
表面上的事情似乎没有任何不同。无论您使用线程还是 Goroutines,都会发生所有相同的上下文切换和状态更改。但是,使用 Threads 和 Goroutines 之间存在一个乍一看可能并不明显的主要区别。
在使用Goroutines的情况下,相同的OS Thread和Core被用于所有的处理。这意味着,从操作系统的角度来看,操作系统线程永远不会进入等待状态;一次也没有。因此,我们在使用thread时丢失的上下文切换指令在使用Goroutines时不会丢失。
本质上,Go已经把IO/阻塞工作变成了操作系统级别的cpu密集型工作。因为所有的上下文切换都发生在应用程序级别,所以我们不会像使用线程时那样,在每次上下文切换中丢失大约12k指令(平均)。在Go中,同样的上下文切换需要花费200纳秒或2.4k指令。调度器还有助于提高缓存行效率和NUMA。这就是为什么我们不需要比虚拟核更多的线程。在Go中,随着时间的推移,有可能完成更多的工作,因为Go调度程序试图使用更少的线程,在每个线程上做更多的工作,这有助于减少操作系统和硬件的负载。
结论 (Conclusion)
Go调度器在设计上考虑了操作系统和硬件工作的复杂性这一点上是非常惊人的。在操作系统级别上,将IO/阻塞工作转化为CPU密集型工作的能力是我们在利用更多CPU容量方面取得的巨大胜利。这就是为什么你不需要比你的虚拟内核更多的OS线程。你可以合理地期望每个虚拟核只使用一个OS线程来完成所有的工作(CPU和IO/阻塞密集)。这样做对于网络应用程序和其他不需要阻塞OS线程的系统调用的应用程序是可能的。
作为开发人员,您仍然需要根据您正在处理的工作类型来了解您的应用程序在做什么。你不能创建无限数量的 Goroutine 并期望惊人的性能。少即是多,但通过理解这些 Go-scheduler 语义,您可以做出更好的工程决策。在下一篇文章中,我将探讨以保守的方式利用并发来获得更好性能的想法,同时仍然平衡您可能需要添加到代码中的复杂性。
发表回复